Anderson, Jennifer L. “Nature’s Currency: The Atlantic Mahogany Trade and the Commodification of Nature in the Eighteenth Century.” Early American Studies: An Interdisciplinary Journal 2, no. 1 (2004): 47–80.
Åström, Sven-Erik. “English Timber Imports from Northern Europe in the Eighteenth Century.”
Scandinavian Economic History Review 18, no. 1 (January 1, 1970): 12–32.
https://doi.org/10.1080/03585522.1970.10415590.
Babones, Salvatore, and Christopher Chase-Dunn. Routledge International Handbook of World-Systems Analysis. Routledge, 2012.
Barbier, Edward B. Scarcity and Frontiers: How Economies Have Developed Through Natural Resource Exploitation. Cambridge: Cambridge University Press, 2011.
Beattie, James, Edward Melillo, and Emily O’Gorman. “Rethinking the British Empire through Eco-Cultural Networks: Materialist-Cultural Environmental History, Relational Connections and Agency.”
Environment and History 20, no. 4 (November 1, 2014): 561–75.
https://doi.org/10.3197/096734014X14091313617406.
Beckert, Sven. Empire of Cotton: A Global History. Reprint edition. Vintage, 2015.
Beinart, William, and Lotte Hughes. Environment and Empire. 1st ed. Oxford: Oxford University Press, 2007.
Bennett, Brett M. “A Global History of Australian Trees.”
Journal of the History of Biology 44, no. 1 (2011): 125–45.
https://doi.org/10.1007/s10739-010-9243-7.
Borgström, Georg. “Ghost Acreage.” In The Future of Nature: Documents of Global Change, edited by Libby Robin, Sverker Sorlin, and Paul Warde, 40–50. NewHaven: Yale University Press, 2013.
———. The Hungry Planet: The Modern World at the Edge of Famine. Macmillan, 1972.
Brockway, Lucile H. “Science and Colonial Expansion: The Role of the British Royal Botanic Gardens.” American Ethnologist 6, no. 3 (1979): 449–65.
———. Science and Colonial Expansion: The Role of the British Royal Botanic Gardens. Yale University Press, 2002.
Clifford, Jim. “London’s Soap Industry and the Development of Global Ghost Acres in the Nineteenth Century.”
Environment and History Fast Track (2020).
https://doi.org/10.3197/096734019X15463432086982.
Coclanis, Peter A. “Ten Years After: Reflections on Kenneth Pomeranz’s The Great Divergence.”
Historically Speaking 12, no. 4 (September 4, 2011): 10–12.
https://doi.org/10.1353/hsp.2011.0056.
Cornish, Caroline. Curating Science in an Age of Empire : Kew’s Museum of Economic Botany, 2013.
Cronon, William. Nature’s Metropolis: Chicago and the Great West. New York: W. W. Norton, 1991.
Curry-Machado, Jonathan, ed. Global Histories, Imperial Commodities, Local Interactions. Palgrave Macmillan, 2013.
Cushman, Gregory T. Guano and the Opening of the Pacific World: A Global Ecological History. Cambridge University Press, 2013.
Dean, Warren. Brazil and the Struggle for Rubber: A Study in Environmental History. Cambridge University Press, 2002.
———. With Broadax and Firebrand: The Destruction of the Brazilian Atlantic Forest. University of California Press, 1997.
Drayton, Richard Harry. Nature’s Government: Science, Imperial Britain, and the “Improvement” of the World. Yale University Press, 2000.
Friis, Cecilie, Jonas Østergaard Nielsen, Iago Otero, Helmut Haberl, Jörg Niewöhner, and Patrick Hostert. “From Teleconnection to Telecoupling: Taking Stock of an Emerging Framework in Land System Science.”
Journal of Land Use Science 11, no. 2 (March 3, 2016): 131–53.
https://doi.org/10.1080/1747423X.2015.1096423.
Goss, Andrew. “Building the World’s Supply of Quinine: Dutch Colonialism and the Origins of a Global Pharmaceutical Industry.”
Endeavour 38, no. 1 (March 2014): 8–18.
https://doi.org/10.1016/j.endeavour.2013.10.002.
Grove, Richard H. Green Imperialism: Colonial Expansion, Tropical Island Edens and the Origins of Environmentalism, 1600-1860. Cambridge University Press, 1996.
Henriques, Sofia Teives, and Paul Warde. “Fuelling the English Breakfast: Hidden Energy Flows in the Anglo-Danish Trade 1870–1913.”
Regional Environmental Change, May 30, 2017, 1–13.
https://doi.org/10.1007/s10113-017-1166-9.
Hoffman, Philip T. “Comment on Ken Pomeranz’s The Great Divergence.”
Historically Speaking 12, no. 4 (September 4, 2011): 16–17.
https://doi.org/10.1353/hsp.2011.0060.
Hornborg, Alf. “Footprints in the Cotton Fields: The Industrial Revolution as Time–Space Appropriation and Environmental Load Displacement.”
Ecological Economics 59, no. 1 (August 5, 2006): 74–81.
https://doi.org/10.1016/j.ecolecon.2005.10.009.
Hornborg, Alf, John Robert McNeill, and Juan Martínez Alier. Rethinking Environmental History: World-System History and Global Environmental Change. Rowman Altamira, 2007.
Infante-Amate, Juan, Brandon Luedtke, Joshua MacFadyen, Jonathan Robins, and Kate Stevens. “Fats of the Land: New Histories of Agricultural Oils.” Agricultural History 93, no. 3 (2019): 520–46.
Innis, Harold Adams, and Daniel Drache. Staples, Markets, and Cultural Change Selected Essays. Montreal, Que.: McGill-Queen’s University Press, 1995.
Iriarte-Goñi, Iñaki, and María-Isabel Ayuda. “Not Only Subterranean Forests: Wood Consumption and Economic Development in Britain (1850–1938).”
Ecological Economics 77 (May 1, 2012): 176–84.
https://doi.org/10.1016/j.ecolecon.2012.02.029.
Isenberg, Andrew C. The Destruction of the Bison, 2001.
John Tully. “A Victorian Ecological Disaster: Imperialism, the Telegraph, and Gutta-Percha.”
Journal of World History 20, no. 4 (2009): 559–79.
https://doi.org/10.1353/jwh.0.0088.
Jones, E. L. The European Miracle: Environments, Economies, and Geopolitics in the History of Europe and Asia. 3rd ed. Cambridge: Cambridge University Press, 2003.
Jr, Alfred W. Crosby. The Columbian Exchange: Biological and Cultural Consequences of 1492, 30th Anniversary Edition. 30 edition. Westport, Conn: Praeger, 2003.
Kennedy, Donald, and Marjorie Lucks. “Rubber, Blight, and Mosquitoes: Biogeography Meets the Global Economy.”
Environmental History 4, no. 3 (July 1, 1999): 369–83.
https://doi.org/10.2307/3985132.
Krausmann, Fridolin, Heinz Schandl, and Rolf Peter Sieferle. “Socio-Ecological Regime Transitions in Austria and the United Kingdom.”
Ecological Economics 65, no. 1 (March 15, 2008): 187–201.
https://doi.org/10.1016/j.ecolecon.2007.06.009.
Kumar, Deepak, Vinita Damodaran, and Rohan D’Souza. The British Empire and the Natural World: Environmental Encounters in South Asia. Oxford University Press, 2011.
Liu, Jianguo, Vanessa Hull, Mateus Batistella, Ruth DeFries, Thomas Dietz, Feng Fu, Thomas Hertel, et al. “Framing Sustainability in a Telecoupled World.”
Ecology and Society 18, no. 2 (June 17, 2013).
https://doi.org/10.5751/ES-05873-180226.
Lower, Arthur R. M. Great Britain’s Woodyard: British America and the Timber Trade, 1763-1867. Montreal: McGill-Queen’s University Press, 1973.
———. North American Assault on the Canadian Forest: History of the Lumber Trade Between Canada and the United States. New ed of 1938 ed edition. Greenwood Press,London, n.d.
MacFadyen, Joshua. Flax Americana: A History of the Fibre and Oil That Covered a Continent. Montreal: McGill-Queen’s Press, 2018.
McCook, Stuart. Coffee Is Not Forever: A Global History of the Coffee Leaf Rust. Ohio University Press, 2019.
———. “The Neo-Columbian Exchange: The Second Conquest of the Greater Caribbean, 1720-1930.” Article, 2011.
http://atrium.lib.uoguelph.ca/xmlui/handle/10214/3161.
McCracken, Donal P. Gardens of Empire: Botanical Institutions of the Victorian British Empire. Leicester University Press, 1997.
McNeill, J. R. “Cheap Energy and Ecological Teleconnections of the Industrial Revolution, 1780–1920S.”
Environmental History 24, no. 3 (July 1, 2019): 463–533.
https://doi.org/10.1093/envhis/emz006.
Mintz, Sidney Wilfred. Sweetness and Power: The Place of Sugar in Modern History. Penguin Books, 1986.
Moore, J. W. “‘Amsterdam Is Standing on Norway’ Part I: The Alchemy of Capital, Empire and Nature in the Diaspora of Silver, 1545–1648.” Journal of Agrarian Change 10, no. 1 (2010): 33–68.
———. “‘Amsterdam Is Standing on Norway’ Part II: The Global North Atlantic in the Ecological Revolution of the Long Seventeenth Century.” Journal of Agrarian Change 10, no. 2 (2010): 188–227.
———. “Environmental Crises and the Metabolic Rift in World-Historical Perspective.” Organization & Environment 13, no. 2 (2000): 123.
———. “Silver, Ecology, and the Origins of the Modern World, 1450–1640.” Rethinking Environmental History: World-System History and Global Environmental Change, 2007, 123–42.
———. “Sugar and the Expansion of the Early Modern World-Economy Commodity Frontiers, Ecological Transformation, and Industrialization.” Review- Fernand Braudel Center 23, no. 3 (2000): 409–433.
———. “The Modern World-System as Environmental History? Ecology and the Rise of Capitalism.” Theory and Society 32, no. 3 (2003): 307–377.
Morse, Kathryn Taylor. The Nature of Gold: An Environmental History of the Klondike Gold Rush. University of Washington Press, 2003.
Müller, Simone M. “Hidden Externalities: The Globalization of Hazardous Waste.”
Business History Review 93, no. 1 (ed 2019): 51–74.
https://doi.org/10.1017/S0007680519000357.
O’Rourke, Kevin. The International Trading System, Globalization and History. Edward Elgar Publ., 2005.
Outland, Robert B. “Suicidal Harvest: The Self-Destruction of North Carolina’s Naval Stores Industry.” The North Carolina Historical Review 78, no. 3 (2001): 309–44.
———. Tapping the Pines: The Naval Stores Industry in the American South. Baton Rouge: Louisiana State University Press, 2004.
Pawson, E. “Plants, Mobilities and Landscapes: Environmental Histories of Botanical Exchange.” Geography Compass 2, no. 5 (2008): 1464–1477.
Peace, Thomas, Jim Clifford, and Judy Burns. “Maitland’s Moment: Turning Nova Scotian Forests into Ships for the Global Commodity Trade.” In Moving Natures: Mobility and Environment in Canadian History, edited by Colin Coates, Ben Bradley, and Jay Young, 27–48. Canadian History and Environment. Calgary: University of Calgary Press, 2016.
Pomeranz, Kenneth. “Ten Years After: Responses and Reconsiderations.”
Historically Speaking 12, no. 4 (September 4, 2011): 20–25.
https://doi.org/10.1353/hsp.2011.0051.
———. The Great Divergence: China, Europe, and the Making of the Modern World Economy. Revised. Princeton University Press, 2001.
Richards, John F. The Unending Frontier: An Environmental History of the Early Modern World. University of California Press, 2006.
Robins, Jonathan. “‘Imbibing the Lesson of Defiance’: Oil Palms and Alcohol in Colonial Ghana, 1900–40.”
Environmental History 23, no. 2 (April 1, 2018): 293–317.
https://doi.org/10.1093/envhis/emx135.
———. “Oil Boom: Agriculture, Chemistry, and the Rise of Global Plant Fat Industries, ca. 1850–1920.”
Journal of World History 29, no. 3 (2018): 313–42.
https://doi.org/10.1353/jwh.2018.0033.
Robins, Jonathan E. “Smallholders and Machines in the West African Palm Oil Industry, 1850–1950.”
African Economic History 46, no. 1 (May 23, 2018): 69–103.
https://doi.org/10.1353/aeh.2018.0002.
Roersch van der Hoogte, Arjo, and Toine Pieters. “Science in the Service of Colonial Agro-Industrialism: The Case of Cinchona Cultivation in the Dutch and British East Indies, 1852–1900.”
Studies in History and Philosophy of Science Part C: Studies in History and Philosophy of Biological and Biomedical Sciences 47, Part A (September 2014): 12–22.
https://doi.org/10.1016/j.shpsc.2014.05.019.
Rooth, Tim. “Replenishing the Earth: The Settler Revolution and the Rise of the Anglo-World, 1783–1939 – By James Belich.”
The Economic History Review 63, no. 2 (May 1, 2010): 536–37.
https://doi.org/10.1111/j.1468-0289.2009.00519_11.x.
Ross, Corey. Ecology and Power in the Age of Empire: Europe and the Transformation of the Tropical World. Oxford University Press, 2017.
———. “The Tin Frontier: Mining, Empire, and Environment in Southeast Asia, 1870s–1930s.”
Environmental History 19, no. 3 (July 1, 2014): 454–79.
https://doi.org/10.1093/envhis/emu032.
Schiebinger, Londa L. Plants and Empire: Colonial Bioprospecting in the Atlantic World. Harvard University Press, 2004.
Sharma, Jayeeta. Empire’s Garden: Assam and the Making of India. Durham N.C.: Duke University Press Books, 2011.
———. “Food and Empire.” In The Oxford Handbook of Food History, 241. Oxford University Press New York, 2012.
Shoemaker, Nancy. “Whale Meat in American History.” Environmental History 10, no. 2 (2005): 269–94.
Theodoridis, Dimitrios. “The Ecological Footprint of Early-Modern Commodities Coefficients of Land Use per Unit of Product.” Göteborg Papers in Economic History, no. 21 (February 2017): 1–86.
Theodoridis, Dimitrios, Paul Warde, and Astrid Kander. “Trade and Overcoming Land Constraints in British Industrialization: An Empirical Assessment.”
Journal of Global History 13, no. 3 (November 2018): 328–51.
https://doi.org/10.1017/S1740022818000189.
Tucker, Richard P. Insatiable Appetite: The United States and the Ecological Degradation of the Tropical World. Lanham: Rowman & Littlefield Publishers, 2007.
Vries, Jan de. “The Great Divergence after Ten Years: Justly Celebrated yet Hard to Believe.”
Historically Speaking 12, no. 4 (September 4, 2011): 13–15.
https://doi.org/10.1353/hsp.2011.0058.
Wallerstein, Immanuel. The Capitalist World-Economy. Cambridge University Press, 1979.
———. The Modern World-System I: Capitalist Agriculture and the Origins of the European World-Economy in the Sixteenth Century. Berkeley: University of California Press, 2011.
Warde, Paul. “Trees, Trade and Textiles: Potash Imports and Ecological Dependency in British Industry, c.1550–1770.” Past & Present 240, no. 1 (August 1, 2018): 47–82.
Weaver, John C. The Great Land Rush and the Making of the Modern World, 1650-1900. Montreal: McGill-Queen’s University Press, 2006.
Webb, James L. A. Tropical Pioneers: Human Agency and Ecological Change in the Highlands of Sri Lanka, 1800-1900. Ohio University Press, 2002.
WHITE, SAM. “From Globalized Pig Breeds to Capitalist Pigs: A Study in Animal Cultures and Evolutionary History.” Environmental History 16, no. 1 (January 1, 2011): 94–120.
Wilk, Richard. “The Extractive Economy: An Early Phase of the Globalization of Diet, and Its Environmental Consequences.” In Rethinking Environmental History: World-System History and Global Environmental Change, edited by Alf Hornborg, John Robert McNeill, and Juan Martínez Alier. Rowman Altamira, 2007.
Williams, Michael. Deforesting the Earth : From Prehistory to Global Crisis. University of Chicago Press, 2003.
Wong, R. Bin. “Economic History in the Decade after The Great Divergence.”
Historically Speaking 12, no. 4 (September 4, 2011): 17–19.
https://doi.org/10.1353/hsp.2011.0049.
Woods, R. J. H. “From Colonial Animal to Imperial Edible: Building an Empire of Sheep in New Zealand, ca. 1880-1900.”
Comparative Studies of South Asia, Africa and the Middle East 35, no. 1 (January 1, 2015): 117–36.
https://doi.org/10.1215/1089201X-2876140.
Woods, Rebecca J. H. The Herds Shot Round the World: Native Breeds and the British Empire, 1800–1900. Chapel Hill: The University of North Carolina Press, 2017.
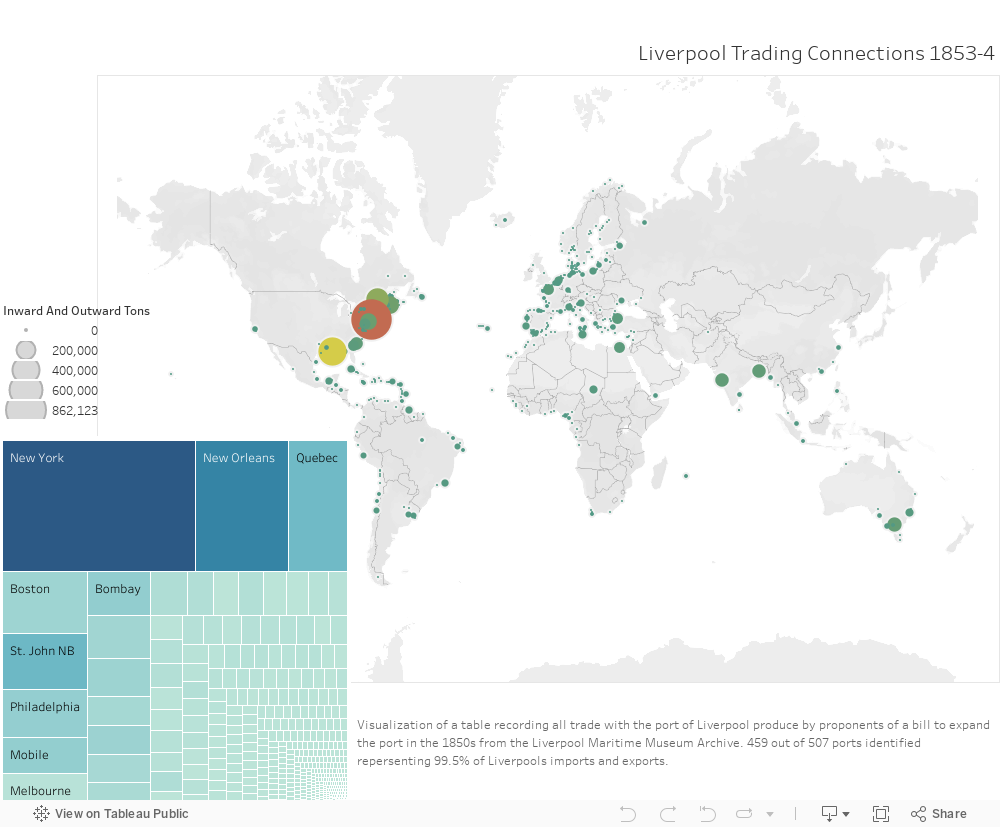

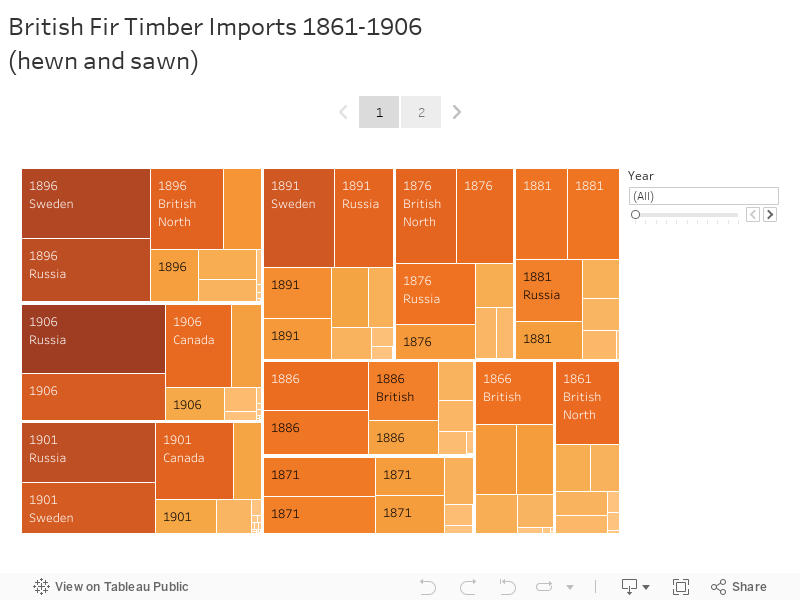
 David Fouser
David Fouser