London’s Text-Mined Hinterlands for the Social Science History Association
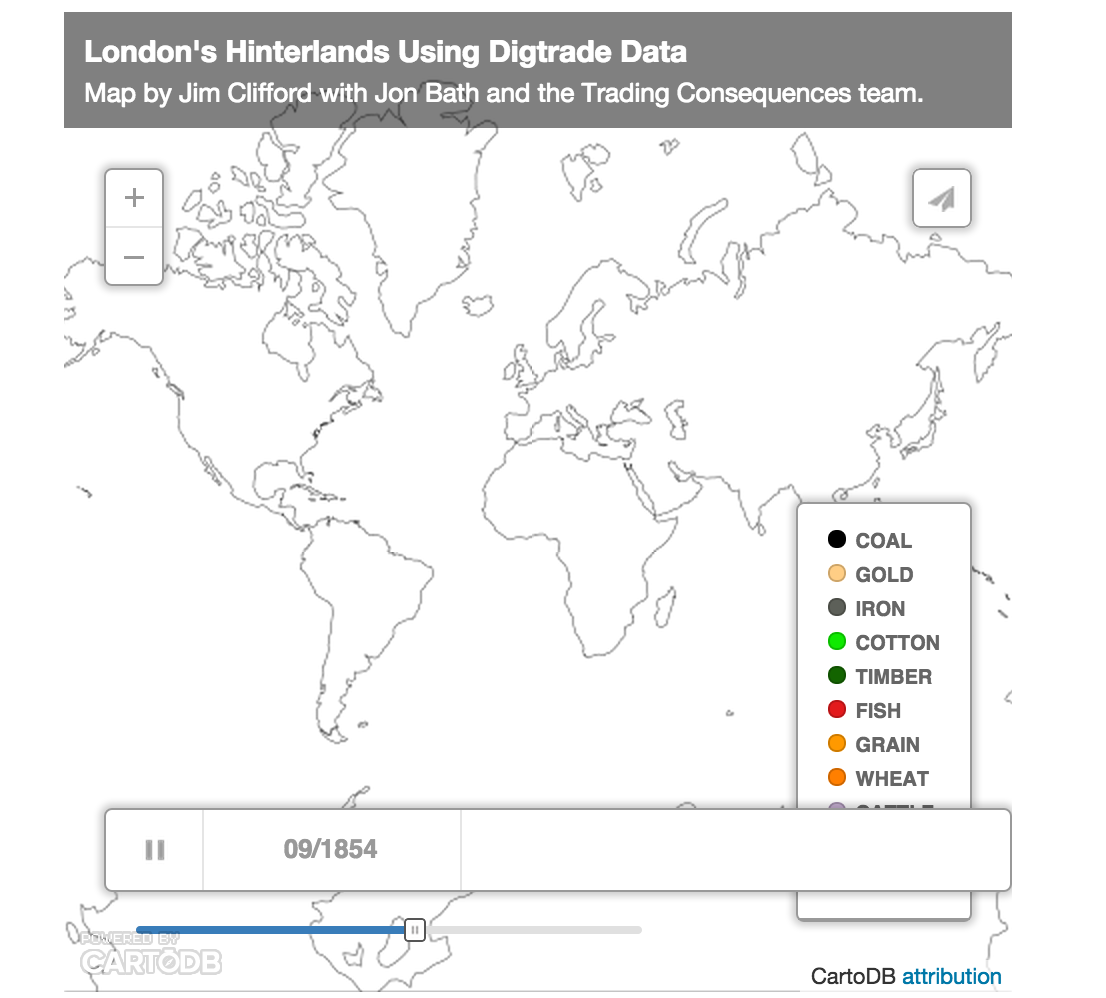
The map below visualizes the text-mined data produced by the Trading Consequences project. We queried the database to identify all the commodities with a strong relationship to London and then found every other location where the text mining pipeline identified a relationship those commodities at least 10 times in a given year. This results in 111,977 rows of data, each representing between 2841 and 10 commodity-place relationships. I will present this data visualization to the Social Science History Association meeting in Toronto this November.
The map above uses CartoDB’s Torque Cat animation to visualize the data as it changes over time. It only distinguishes 10 different commodities, which is already too many to really follow, and displays the remaining commodities in the Other category. The word cloud below shows all of the commodities and ranks them by the number of places and number of years they met the 10 relationships threshold (i.e. the words are bigger if a commodity had a lot of mined relationships with different places and these relationships remained consistent across the whole century).
It is also possible to look at all of the data from the whole of the nineteenth century to see the the locations with a high intensity of relationships with numerous commodities that also have a strong relationship with London.
[This map looks better when you zoom in.]
I should note that this data does not confirm a direct relationship with London and not all of these locations are a part of the city’s increasingly global hinterlands. Some locations would be competing markets sourcing the same materials or producing the same goods as London. British ports were also waystations where goods from the world were transhipped and sent on to other European centres. The text mining identified when a commodity term, like sugar, was in the same sentence as a place name. The text mining shows a strong correlation between London and sugar and a strong correlation between Cuba and sugar. In this case Cuba, I know from other sources, it was among the numerous suppliers of sugar to London. We cannot simply assume, however, that the strong correlation between Leather and Calais in 1822 meant the French port supplied London with Leather in that year. They could be a market for London’s leather or a competitor. To focus the map on London’s hinterlands exclusively, I would need to filter out results based on additional research and an extensive ground-truthing exercise. It would probably be more accurate to say these maps helps illuminate the geography of commodities related to London in the nineteenth century, but this data and the visualizations remain a starting point for further research (like the research I’m doing with Andrew Watson on leather).
You can download the data as a CSV file with this link.
Here is the abstract for the SSHA paper I’m co-authoring with Bea Alex and Uta Hinrichs:
Visualizing Text Mined Geospatial Results: Exploring the Trading Consequences Database.
 I am working on an abstract for the
I am working on an abstract for the 
 From the Trading Consequences Blog: Today we are delighted to officially announce the launch of Trading Consequences! Over the course of the last two years the
From the Trading Consequences Blog: Today we are delighted to officially announce the launch of Trading Consequences! Over the course of the last two years the 

