Category: Digital History
British Timber Imports 1861-1906

Michael Williams (2003) uses data from Arthur Lower (1973) to confirm Sven-Erik Åström’s (1970) conclusion that mid-nineteenth century British North American timber exports to Britain were only a temporary “episode” in the long term dominance of the British timber market by Northern Europe. William’s charts use Lower’s data from 1790 to 1870 suggest a significant decline in British North American exports by the start of the 1870s. However, British import statistics from the Nineteenth Century and Twentieth Century House of Commons Sessional Papers confirm British North America and later Canada (without Newfoundland) remained major exporters of fir through to the early twentieth century. British North America did drop behind Sweden and Russia to become the third leading exporter to the United Kingdom in 1886, and they remained third through to 1906. The end of the tariffs do appear to have helped Northern European exporters after the 1860s, but this did not cause a collapse in exports from British North America.
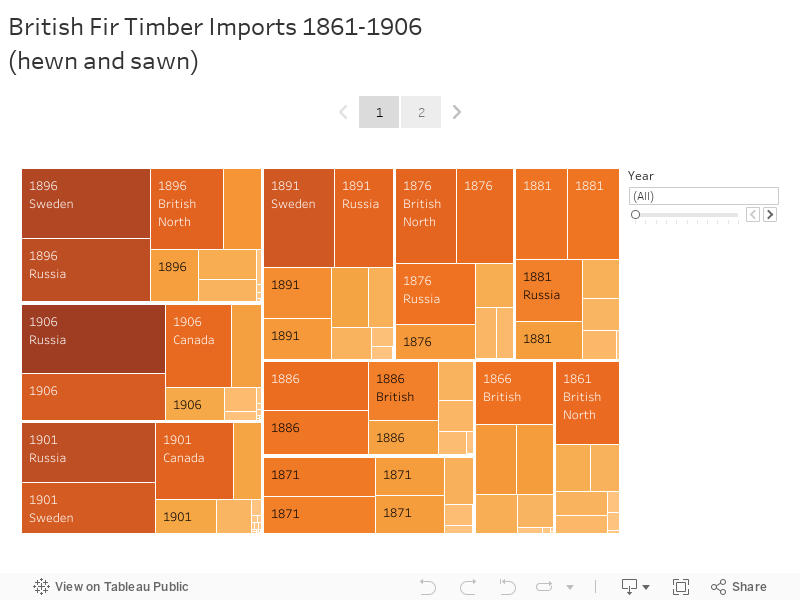
Click the expand button in the bottom right to see the full sized visualization.
![]()
New Books Network Podcast
 David Fouser interviewed me about by book for the New Books Network Podcast series. Here is his description of the book and a link to the podcast:
David Fouser interviewed me about by book for the New Books Network Podcast series. Here is his description of the book and a link to the podcast:
In West Ham and the River Lea: A Social and Environmental History of London’s Industrialized Marshlands, 1839-1914 (University of British Columbia Press, 2017), Jim Clifford brings together histories of water and river systems, urban history, environmental history, and labor history. Using archival materials with a particular focus on Ordnance Survey maps and historical GIS (geographical information systems), he explores Greater London’s second important river, the Lea, using it as a lens through which to track industrialization in the 19th and early 20th century. He shows how the River Lea made West Ham an attractive area for industrial development, drawing manufacturing and chemical plants to the area. [read more and listen to the podcast here]
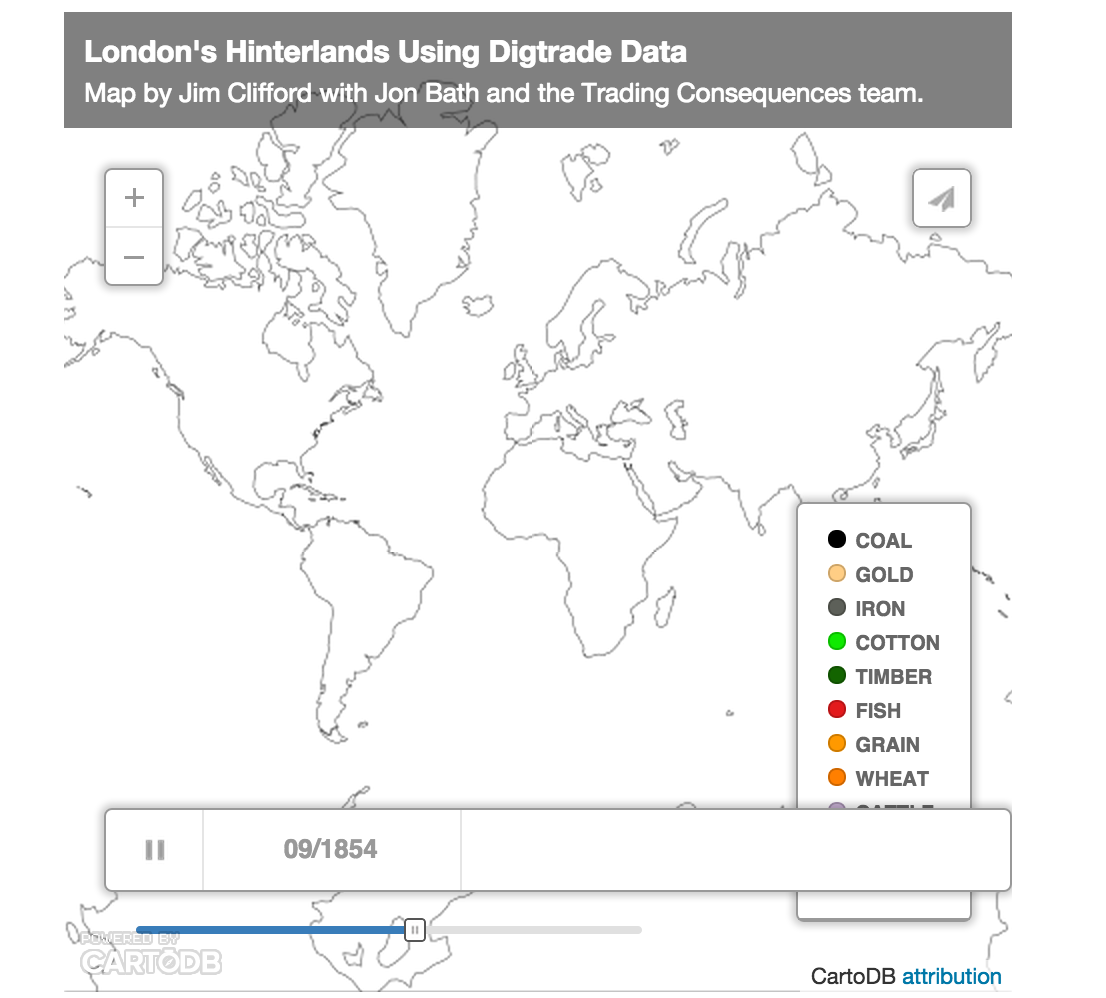
London’s Text-Mined Hinterlands for the Social Science History Association
The map below visualizes the text-mined data produced by the Trading Consequences project. We queried the database to identify all the commodities with a strong relationship to London and then found every other location where the text mining pipeline identified a relationship those commodities at least 10 times in a given year. This results in 111,977 rows of data, each representing between 2841 and 10 commodity-place relationships. I will present this data visualization to the Social Science History Association meeting in Toronto this November.
The map above uses CartoDB’s Torque Cat animation to visualize the data as it changes over time. It only distinguishes 10 different commodities, which is already too many to really follow, and displays the remaining commodities in the Other category. The word cloud below shows all of the commodities and ranks them by the number of places and number of years they met the 10 relationships threshold (i.e. the words are bigger if a commodity had a lot of mined relationships with different places and these relationships remained consistent across the whole century).
It is also possible to look at all of the data from the whole of the nineteenth century to see the the locations with a high intensity of relationships with numerous commodities that also have a strong relationship with London.
[This map looks better when you zoom in.]
I should note that this data does not confirm a direct relationship with London and not all of these locations are a part of the city’s increasingly global hinterlands. Some locations would be competing markets sourcing the same materials or producing the same goods as London. British ports were also waystations where goods from the world were transhipped and sent on to other European centres. The text mining identified when a commodity term, like sugar, was in the same sentence as a place name. The text mining shows a strong correlation between London and sugar and a strong correlation between Cuba and sugar. In this case Cuba, I know from other sources, it was among the numerous suppliers of sugar to London. We cannot simply assume, however, that the strong correlation between Leather and Calais in 1822 meant the French port supplied London with Leather in that year. They could be a market for London’s leather or a competitor. To focus the map on London’s hinterlands exclusively, I would need to filter out results based on additional research and an extensive ground-truthing exercise. It would probably be more accurate to say these maps helps illuminate the geography of commodities related to London in the nineteenth century, but this data and the visualizations remain a starting point for further research (like the research I’m doing with Andrew Watson on leather).
You can download the data as a CSV file with this link.
Here is the abstract for the SSHA paper I’m co-authoring with Bea Alex and Uta Hinrichs:
Visualizing Text Mined Geospatial Results: Exploring the Trading Consequences Database.
Trading Consequences Cinchona Data in Voyant Tools
 I am working on an abstract for the ESEH in France next summer. I plan to focus on the role of an industrialist, J.E. Howard, in supporting the efforts of British government officials and economic botanists to establish cinchona plantations in Asia. I’ve done a lot of archival research on this topic, but I thought it would be interesting to see what I could find in the Trading Consequences database. The Location Cloud Visualization clearly shows the geographic transfer of cinchona to India and Ceylon, but I needed to dig down past our web visualizations to see what the database has to say about a particular person. To do this, I extracted every sentence that mentions the commodity cinchona in the Trading Consequences corpus, ordered them by their year and exported a text file from the database. This yields a file with 3762 sentences that mention cinchona.
I am working on an abstract for the ESEH in France next summer. I plan to focus on the role of an industrialist, J.E. Howard, in supporting the efforts of British government officials and economic botanists to establish cinchona plantations in Asia. I’ve done a lot of archival research on this topic, but I thought it would be interesting to see what I could find in the Trading Consequences database. The Location Cloud Visualization clearly shows the geographic transfer of cinchona to India and Ceylon, but I needed to dig down past our web visualizations to see what the database has to say about a particular person. To do this, I extracted every sentence that mentions the commodity cinchona in the Trading Consequences corpus, ordered them by their year and exported a text file from the database. This yields a file with 3762 sentences that mention cinchona.
Uploading this data into Voyant Tools makes it easy to explore some of the patterns in the text as it changes over the course of the nineteenth century. For example, we can see the initial importance of India (which would include mentions of the East India Company) and the growing significance of Ceylon and Java as the century went on. It is also notable that Peru and Peruvian were relatively less significant locations in these British government documents.
Using the same tool, we can see the rise and decline in popularity of an alternative spelling of cinchona, “chinchona”, during the middle of the 19th century.

More to the point, we can search for the last names of five of the key individuals involved in the transfer of cinchona: Clement Markham, Richard Spruce, the father and son, William and Joseph Hooker, and John Eliot Howard. Markham was a Indian Office geographer who led an exhibition to Peru to steal cinchona seeds. Spruce, a botanist, collected further seeds from New Granada. The Hookers were both directors of Kew Gardens, with Joseph taking over from his father in 1865. Howard was one of the sons in the Howard & Sons company, which produced much of the quinine manufactured in Britain. In addition to his expertise as a manufacturer, Howard was a leading expert on the botany of cinchona. The visualization below shows that while Markham, Spruce and William Hooker were key figures in the initial planning and transfers of the early 1860s, Howard gains significance in the corpus in the decades that follow.
The real power of Voyant is that once you identify an interesting trend in the data, it is possible to click on the spike for Howard in the chart above and update some of the other visualizations. Below you can see “Howard” as a key work in context during the spike and further down you can see the actual sentences where Howard is mentioned. With a little more work I could have included the URL for the original document page.